
概要
試行錯誤で進化する強化学習の力
教師あり学習や教師なし学習と並ぶ機械学習の一分野である「強化学習(Reinforcement Learning, RL)」。明確な「正解」データを与えるのではなく、エージェント(AI)が環境と相互作用しながら、「試行錯誤」を通じて累積的な「報酬」を最大化するように行動を学習していく手法です。
囲碁AI「AlphaGo」の衝撃的な成功により一躍注目を集めましたが、その応用範囲はゲームAIに留まらず、ロボット制御、自動運転、リソース最適化、推薦システム、マーケティングなど、ビジネスにおける複雑な意思決定問題へと急速に広がっています。
本記事では、強化学習の基本的な仕組みと、その多様な応用可能性について解説いたします。
なぜ従来の機械学習だけでは解けない問題があるのか?
教師あり学習は、明確な入力と正解出力のペアが必要です。教師なし学習は、データそのものの構造やパターンを見つけ出すことを目的とします。
しかし、世の中にはこれらの手法だけでは解決が難しい問題が存在します。

強化学習の仕組みと主要なアルゴリズム
強化学習は、以下の要素から構成されます。
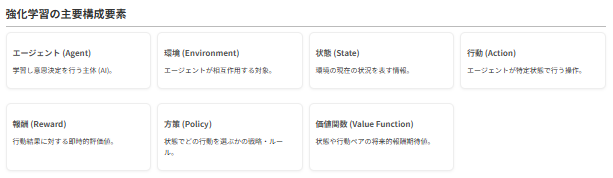
エージェントは、環境の状態を観測し、方策に基づいて行動を選択します。その結果、環境の状態が変化し、エージェントは報酬を受け取ります。この一連の相互作用(試行錯誤)を繰り返しながら、価値関数や方策を更新し、より良い行動戦略を学習していきます。
主要なアルゴリズムには、以下のようなものがあります。

Vision Consultingによる強化学習の導入・活用支援
Vision Consultingは、強化学習技術を活用し、お客様の複雑な意思決定問題の解決や自律システムの構築を支援いたします。
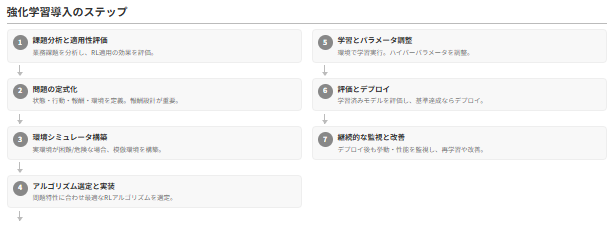
強化学習が切り拓く可能性
強化学習の応用範囲は多岐にわたります。

より汎用的で安全な強化学習へ
強化学習は大きな可能性を秘めている一方で、実応用に向けては以下のような課題と今後の展望があります。
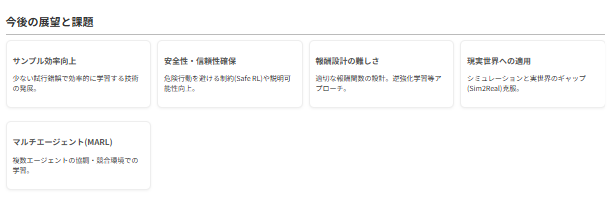
これらの課題克服に向けた研究開発が進むことで、強化学習はより汎用的で信頼性の高い技術となり、自律的な意思決定が求められる様々な分野で中核的な役割を担っていくと考えられます。
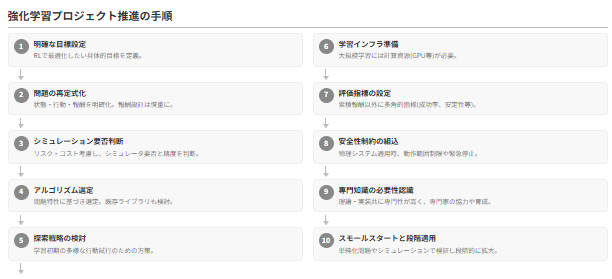
検討手順
強化学習プロジェクトを成功させるために、具体的に検討・実行すべき事項は以下の通りです。
おわりに
強化学習は、明確な正解データなしに、試行錯誤を通じて最適な行動戦略を獲得できる強力な機械学習パラダイムです。
ロボット制御、ゲームAI、各種最適化問題など、従来の手法では解決が難しかった複雑な意思決定タスクにおいて、目覚ましい成果を上げています。報酬設計の難しさや安全性確保といった課題はあるものの、深層学習との融合やアルゴリズムの進化により、その応用範囲はますます広がっています。適切な問題設定、報酬設計、そしてシミュレーション技術の活用が、強化学習プロジェクト成功の鍵となります。
Vision Consultingは、強化学習に関する高度な専門知識とビジネス応用ノウハウに基づき、お客様の課題解決に最適な強化学習ソリューションの構想策定から、環境構築、モデル開発、実装、評価までをトータルで支援いたします。試行錯誤から生まれる知能で、ビジネスの新たな可能性を切り拓きましょう。
➨コンサルティングのご相談はこちらから
補足情報
関連サービス:AI導入コンサルティング、強化学習ソリューション開発、ロボティクスAI開発、シミュレーション環境構築、最適化ソリューション
キーワード:強化学習(RL)、深層強化学習(DRL)、エージェント、環境、状態、行動、報酬、方策、価値関数、Q学習、方策勾配法、Actor-Critic、ロボット制御、ゲームAI、自動運転、最適化、シミュレーション、報酬設計
